Dendra services both those who conduct research and those who manage research assets such as stations, dataloggers, and the resulting metadata concerning station status and sensor health.
The two primary user types are field technicians and researchers.
Field Technicians are part of an organization that uses Dendra to operate their sensor observatory. Field techs conduct station management, monitor datalogger health, and are responsible for station deployment and data curation for a given organization.
Much of the functionality discussed here (in Core Concepts) is aimed at the field technicians of an organization.
Researchers often have no affiliation to an organization, as typically one is not required to access an organization’s publicly available data. Researchers may or may not have a Dendra login.
Dendra is organized around the practical components of a sensor observatory deployment. It reflects the needs of both the role of a curator (observatory manager/data manager/field technician) and the role of the researcher.
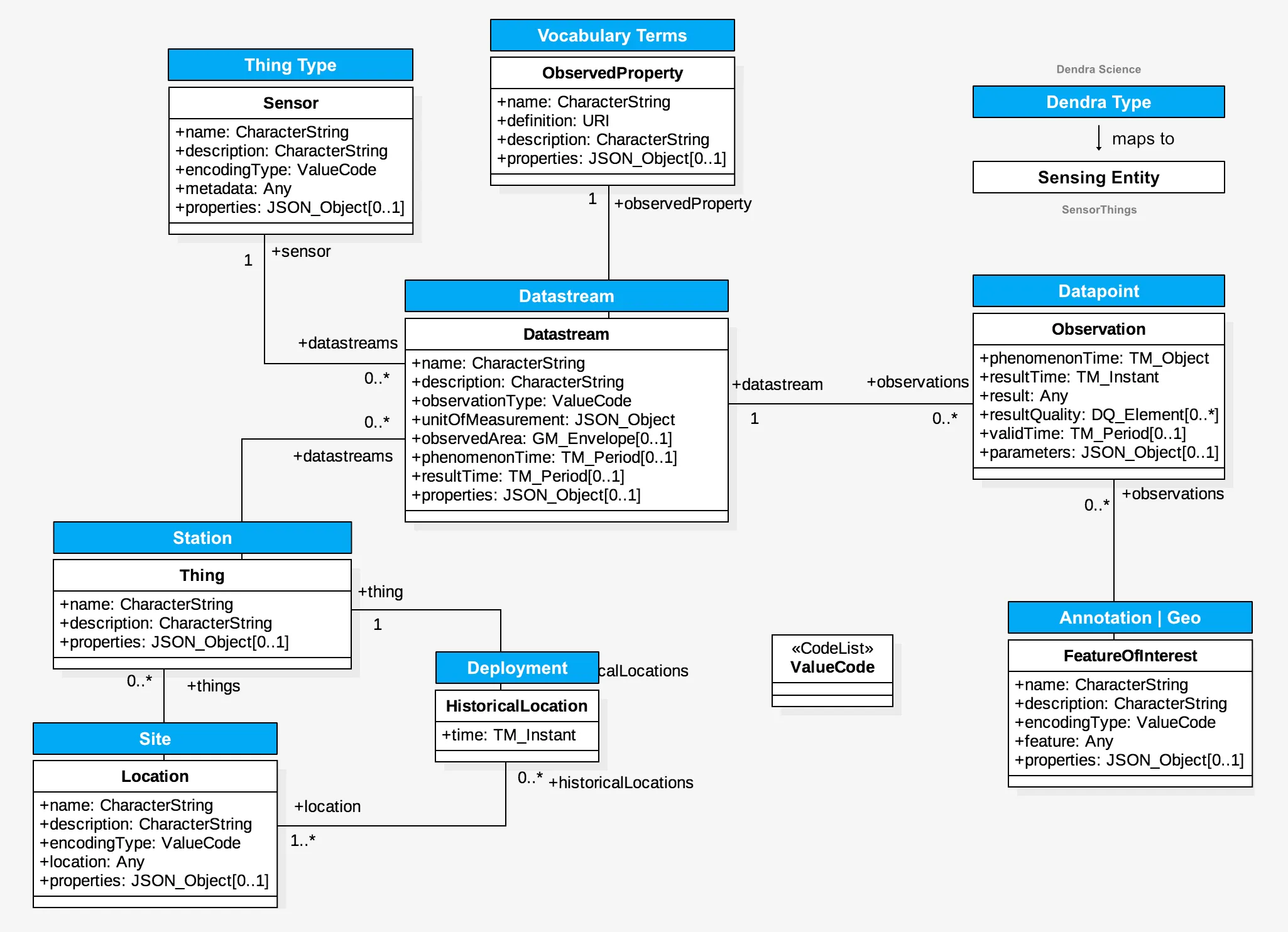
Our system provides a simple hierarchy from organization to station to datastream.
From the top of hierarchy to the bottom:
Organization → Station/Site → Sensor → Datastream → Datapoint.
A station is a datalogger at a location. The sensor is the instrument (thing) used for measurements and attached to a station.
One sensor may have many datastreams.
Our permissions structure for access control (ACL) uses this hierarchy, as does our management interface and annotation system. Many configuration parameters are inheritable. The inheritance can be overridden at any level.
A datastream is a measurement (observation), performed at a particular site (x,y,z), using a particular method of measurement. The Dendra team popularized this concept back in 2008 as a development beyond the Observations Data Model (ODM 1.1) of the time.
The term “datastream” has subsequently found its way into standards such as OGC’s SensorThings . It is a powerful concept for long term monitoring.
The datastream abstracts the method of measurement away from the particular sensor being used and the location of data storage. A 50 year stream gage record will go through many sensors, from float & chain gages to pressure transducers, to laser distance finders, but the stream gage is still reading water level. The fieldname in a datalogger may change (WL_mm, WaterLevel_inches, SGage_m). Units may change, the datalogger may change, but it is still reading stream water level. Dendra uses the datastream to keep track of these changes over time and points the system to each set of data for a time slice in a table with the proper fieldname.
We have the ability to make derived datastreams, which perform the calculations necessary to produce the desired measurement. This places the control back with the researcher, who can review equations and calibrations and change if necessary.
Derived datastreams can also use multiple input datastreams, such as calculated evapotranspiration, absolute humidity, and sap flow. In addition, we have a microservice that can also perform across time interval calculations, such as cumulative rainfall by water year. All derived values are automatically corrected if the source measurement is corrected via annotation.
A key innovation in Dendra is the use of our annotation system to perform dynamic versioning to clean data. All corrections, calculations, and exclusions to data are stored as a JSON document associated with a datastream. The changes are not applied directly to the datapoints themselves.
In code repositories like GitHub, every change or commit to a piece of code has a developer’s name and a timestamp. This is referred to as “versioning”. Most modern repositories have the ability to roll back changes to any previous commit or roll forward to the current commit. This is dynamic versioning.0
With time-series data, the standard practice is to have several copies of the data rated at quality control levels. Raw data are usually unchanged coming from the logger. Corrected data have adjustments and cleaning.
Some systems have a third layer of modeled or complex corrections applied. However, with very long time-series datasets, many corrections can occur over time. These all get overwritten into the “corrected” dataset. If a mistake occurs, it is necessary to start over with the raw data. In some cases, data managers will create copies of the corrected data — statically versioning the dataset.
Dendra’s annotation system is designed to apply the corrections to the datastream’s configuration definition. When someone requests data, all the annotation changes are applied to the raw data as it is retrieved, whether it is an exclusion of bad data or an adjustment or correction calculation on the fly.
This is key to its function. Because it is done on the fly, it can be “rolled back” to a previous state by removing annotations back to a certain date. Users can also invalidate or edit annotations that were done incorrectly, without changing data.
The annotation system, coupled with our derivation system and simple data model, provide enormous flexibility to the system.
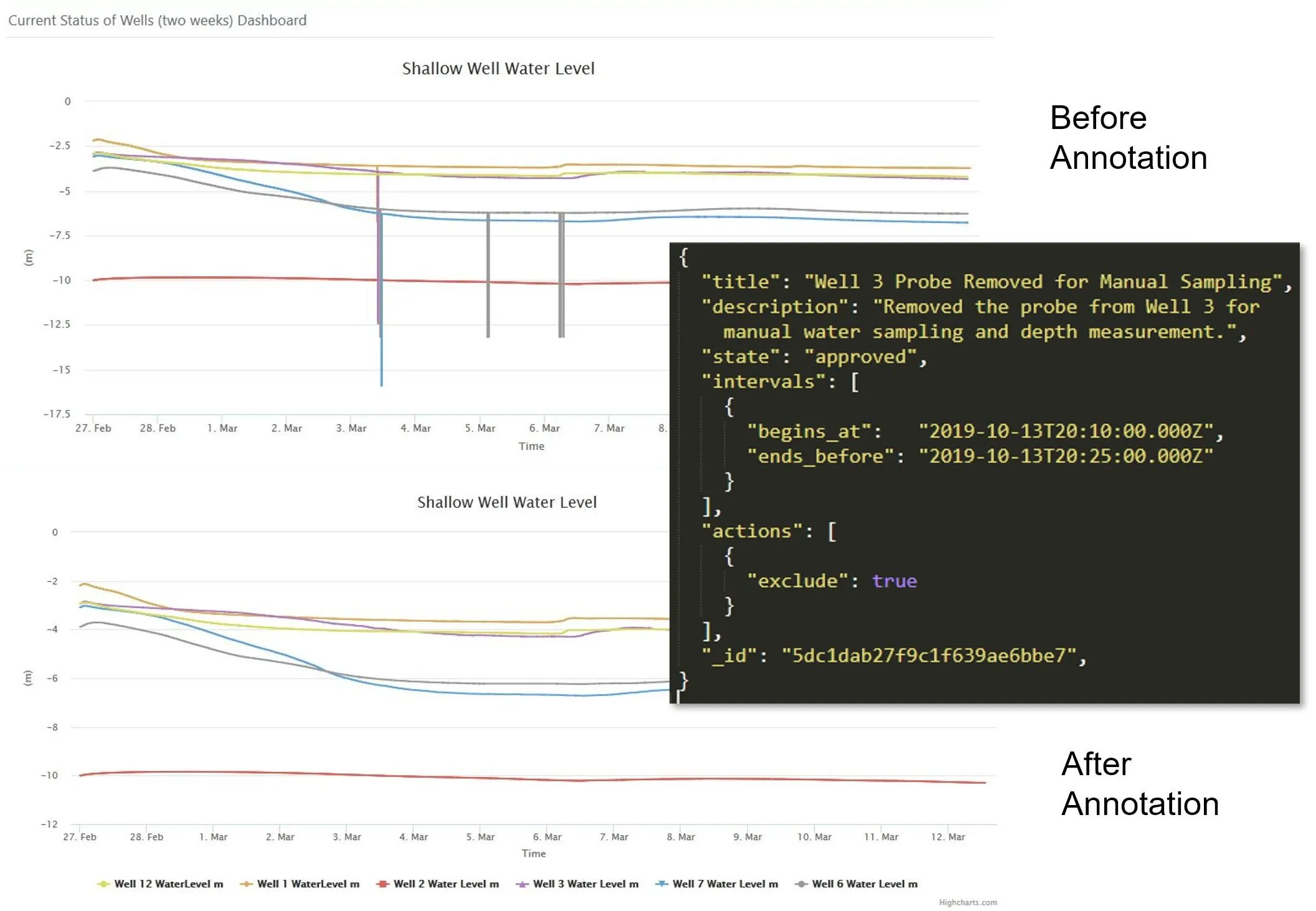
Annotation Example
A correction can be applied to a pressure transducer.
The pressure transducer value will propagate to the derived datastream Well 10 Water Level, since it is derived from the source datastream.
If that annotation is reversed or invalidated, it will instantly revert.